코틀린 심화문법 - 코루틴 Deep Dive
기본적인 이론은, 예전에 정리한 글이 있다.
코루틴 (LightWeight Thread)
- 콜백을 대체하여 비동기 처리를 간단하게 해줌.
- 비동기 처리를 순차적으로 구현할 수 있음.
- 스레드 블러킹을 방지할 수 있음.
코루틴의 구조는 다음과 같다.
코루틴스코프의 LifeCycle 지정.코루틴빌더 {
// Coroutine Scope
}
fun main() {
GlobalScope.launch { // Coroutine Block
delay(1000L)
println("World!")
}
println("Hello, ")
}Hello,
[프로그램 종료]
코루틴 빌더 launch로 만든 { } 내의 부분이 코루틴 블럭(코루틴 스코프)이 된다.
fun main() {
GlobalScope.launch {
delay(1000L)
println("World!")
}
println("Hello, ")
Thread.sleep(2000L)
println("END")
}
Hello,
(1초뒤)
World!
(2초뒤)
End
[프로그램 종료]
sleep 하다가도 코루틴 스코프(=코루틴 블럭) 내로 다시 돌아가서 World를 출력하고 sleep를 다시 진행한다는 것도 알 수 있다.
thread로 했을 때와 같은 동작은 이렇다.
fun main() {
thread {
// delay(1000L)
Thread.sleep(1000L)
println("World!")
}
println("Hello, ")
Thread.sleep(2000L)
println("END")
}
이번엔 코루틴 빌더 launch가 아닌
코루틴 빌더 runblocking을 이용해본다.
결과는 위 예제들과 모두 같다.
fun main() {
GlobalScope.launch {
delay(1000L)
println("World!")
}
println("Hello, ")
runBlocking {
delay(2000L)
}
print("END")
}Hello,
(1초뒤)
Hello, World!
(2초뒤)
END
[프로그램 종료]
이걸 runBlocking 대신 코루틴 빌더 launch를 이용하면
fun main() {
GlobalScope.launch {
delay(1000L)
println("World!")
}
println("Hello, ")
GlobalScope.launch {
delay(2000L)
}
println("END")
}
Hello,
World
[프로그램 종료]
lauch, runBlocking 모두 코루틴 빌더지만
코루틴 빌더 launch를 이용할 경우에는 스코프 다음 영역이 곧바로 실행되지만
코루틴 빌더 runBlocking을 이용할 경우에는 스코프 다음 영역이 곧바로 실행되지 않음을 깨달을 수 있다.
또다른 예제다.
fun main() = runBlocking {
val job = GlobalScope.launch {
delay(3000L)
println("World!")
}
println("Hello, ")
job.join()
}
main함수를 runBlocking 했으므로, runBlocking 내의 모든 구문이 끝나기 전까지 메인함수는 리턴, 종료되지 않는다.
기본적으로 코루틴 빌더는 job을 리턴한다. 이를 활용할 수 있다.
launch를 통해 job을 받았고, 이 job에 대해 join()을 호출하게 되면
job.join() 에서는 이 코루틴 스코프가 끝나기 전까지 기다린다.
비동기 작업이 끝날 때 까지를 기다리는 방식이다.
join을 저기서 하지 않는다면, "Hello," 만 찍히고 프로그램이 종료된다.
그럼 job을 계속 이렇게 관리해줘야하나? 너무 귀찮다.
Structured Concurrency 기법
GlobalScope를 사용하지 않고, runBlocking으로 만든 코루틴 스코프 내에서 launch를 실행하여
코루틴 스코프 적용 범위를 바꾼다.
fun main() = runBlocking {
this.launch {
delay(3000L)
println("World!")
}
println("Hello, ")
}이러면 동일한 기능으로 작동한다.
GlobalScope는 코루틴 스코프의 LifeCycle을 전역적 범위로 지정한 것이다. 그렇기 때문에 runBlocking과 아무런 관련이 없이 개별로 동작한 것이고, this.launch를 통해 코루틴 스코프를 runBlocking과 Structured 시킴으로써 종속적이게 만들어 준 것이다.
코루틴 간의 연관관계를 만드는게 Structured Concurrency이다.
이 World 출력 부분을 이제 함수로 새로 빼서 정의해보자.
이럴 땐 함수에 suspend를 지정해줘야 한다.
코루틴 스코프(=코루틴 블럭) 내에서 suspend를 호출해야, 코루틴 스코프를 언제든지 나갈 수 있다.
코루틴 스코프에 suspend가 없으면 그냥 순차적으로 실행되는 일반 함수랑 차이가 없다.
fun main() = runBlocking {
this.launch {
myWorld()
}
println("Hello, ")
}
suspend fun myWorld() {
delay(3000L)
println("World!")
}suspend 함수는 코루틴 스코프 내, suspend 함수 내에서만 사용이 가능하다.
delay 또한 suspend 함수다.
그리고 재밌는 사실을 알 수 있는데
fun main() = runBlocking {
this.launch {
for (i in 1..100) {
println("A ${i}")
}
}
this.launch {
for (i in 1..100) {
println("B ${i}")
}
}
for(i in 1..100) {
println("C ${i}")
}
}출력 순서가 어떻게 될까?
무조건 C가 먼저 다 찍히고, 그다음 A, 그다음 B가 찍힌다.
코루틴 블럭 내에서 각 statement 실행은 원래 모두 순차적으로 진행되긴 하지만,
예외로 순서가 "또다른 코루틴 블럭 < 일반 statement" 임을 깨달을 수 있다.
launch { // A
launch { // B
}
launch { // C
}
println("Hi")
}A라는 코루틴 블럭 내에서, 코드는 순차적으로 진행되는게 맞는데
println이 항상 먼저 동작하고 -> B -> C 가 동작한다.
일반 statement보다 코루틴 블럭 실행이 항상 늦다는 예외가 있다.
또한, 여기서 A와 B의 순서를 뒤죽박죽 하고 싶으면
fun main() = runBlocking {
this.launch {
for (i in 1..100) {
delay(10L)
println("A ${i}")
}
}
this.launch {
for (i in 1..100) {
delay(10L)
println("B ${i}")
}
}
for(i in 1..100) {
println("C ${i}")
}
}이렇게 하면 된다.
그러면 C가 무조건 먼저 다 찍히고, A와 B가 번갈아서 찍힌다. suspend 함수를 사용했기 때문에 언제든지 스코프 밖을 나갈 수 있는 것.
이해하지 못하더라도, 이 감각을 느끼면 된다.
Dream Code
아래 예제는
코루틴이 비동기라도, 블럭 내부가 일반 코드처럼 기본적으로 순차적으로 실행되게 설계되었다는 것을 보여준다.
fun main() = runBlocking {
val time = measureTimeMillis { // 얼마나 걸렸는지 측정해주는 람다
val one = doSomethingUsefulOne()
val two = doSomethingUsefulTwo()
println("The answer is ${one + two}")
}
println("Completed in $time ms")
}
suspend fun doSomethingUsefulOne(): Int {
delay(1000L)
return 13
}
suspend fun doSomethingUsefulTwo(): Int {
delay(1000L)
return 29
}일반 코드처럼 작성해도 똑같이 순차적으로 진행된다.
= 이것이 Dream Code. 코루틴은 비동기 실행을 순차적으로 만들어줬다는 것을 보여준다.
두 연산이 서로 dependency가 없이 독립적이어서, 동시 실행해도 무방하다면 이렇게 해줄 수도 있다.
async와 await을 이용한다.
fun main() = runBlocking {
val time = measureTimeMillis {
val one = async { doSomethingUsefulOne() }
val two = async {doSomethingUsefulTwo() }
println("The answer is ${one.await() + two.await()}")
}
println("Completed in $time ms")
}
suspend fun doSomethingUsefulOne(): Int {
delay(1000L)
return 13
}
suspend fun doSomethingUsefulTwo(): Int {
delay(1000L)
return 29
}
시작 시점 조정
-> lazy를 이용해서 명시적으로 실행 시점을 지정할 수도 있다.
fun main() = runBlocking {
val time = measureTimeMillis {
val one = async(start = CoroutineStart.LAZY) { doSomethingUsefulOne() }
val two = async(start = CoroutineStart.LAZY) {doSomethingUsefulTwo() }
one.start()
two.start()
println("The answer is ${one.await() + two.await()}")
}
println("Completed in $time ms")
}
suspend fun doSomethingUsefulOne(): Int {
delay(1000L)
return 13
}
suspend fun doSomethingUsefulTwo(): Int {
delay(1000L)
return 29
}
Dispatcher
코루틴이 어떤 스레드 / 어떤 스레드 풀에서 실행되게 할지.
모든 코루틴 빌더들은 Optional로 Dispatcher를 설정할 수 있다.
- Dispatchers.Unconfined : Main Thread
- Dispatchers.Default : Worker Thread
- Dispatchers.IO : Worker Thread
생략할 시, 호출된 Context에서.
IO / Default의 차이는 뭘까?
=>
IO의 경우 대기시간이 있는 네트워크 입출력 등의 작업에 적합한 반면
Default의 경우 대기시간이 없고 지속적으로 CPU의 작업을 필요로 하는 무거운 작업에 적합하다.
withContext
현재 실행되고 있는 코루틴의 컨텍스트를 변경할 때 사용된다. 가장 대표적인 예는 Android 기준으로 http request를 수행하고 그 결과를 화면에 표시한다고 가정하면 아래와 같은 코드가 될 것이다.
GlobalScope.launch(Dispatchers.IO) { //네트워크에서 불러올 데이터
Log.d(TAG,"1")
val answer = doNetworkCall() //이 함수를 보면 3초 delay가 있기때문에 3초뒤에 dispatcherMain 스레드를 실행하게 된다.
withContext(Dispatchers.Main){ //now this thread will run main thread
Log.d(TAG, "2")
TextView.text = answer
}
}
//doNetwork Call()은 delay예시에서 사용했던 suspend function입니다.
suspend fun doNetworkCall():String{
delay(3000L)
return "this is the answer"
}말했듯 코루틴 블럭 내에서는 기본적으로 순차적으로 진행하므로,
작업 스레드의 doNetworkCall() 에서 네트워크 작업이 끝난 뒤에 컨텍스트를 변경하여 메인 스레드에서 텍스트뷰 변경 작업을 하게 된다.
같은 코루틴인데 Context를 전환하는 것이다.
코루틴의 내부 동작 원리 ( in JVM )
There is no magic. 마법은 없다. 결국엔 내부는 콜백 느낌이다.
내가 콜백으로 코드를 구현하는게 아니라, 컴파일러가 콜백으로 만들어주는 것 뿐이다.
코루틴 코드는 CPS(Continuation Passing Style) 로 전환된다.
Continuation 객체는 콜백 리스너 같은 것이다. 상태 정보값을 의미하고
suspend fun의 마지막 파라미터로 계속 넘겨주면서..
이것에 따라 switch - case / when 처럼 labeling을 통해 suspend 함수 내에서 어디서부터 다시 시작할지를 결정한다.
정리
Scope ( 코루틴의 LifeCycle 결정 )
- GlobalScope
- CoroutineScope
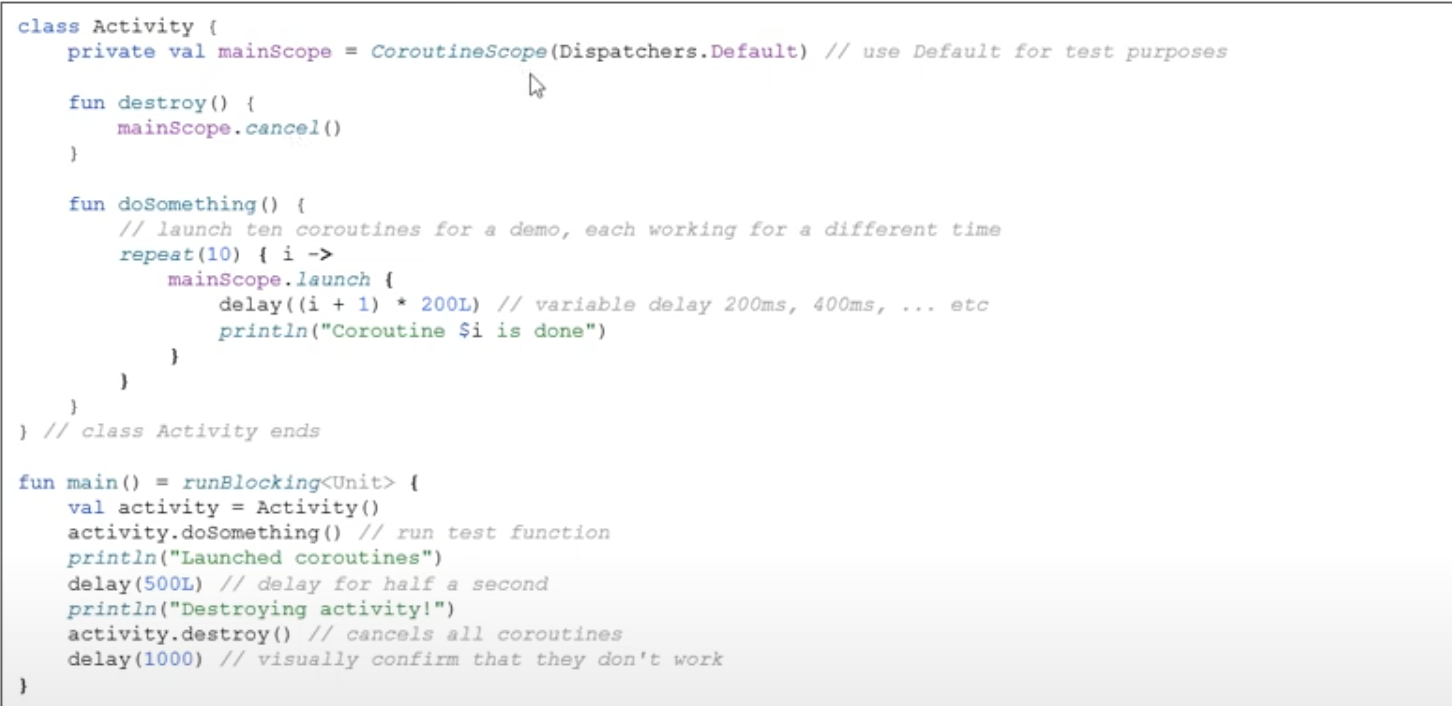
- GlobalScope는 Signleton이기 때문에 Application이 살아있는 동안은 계속 살아있다.
- CoroutineScope()는 객체를 생성하기 때문에 호출한 객체가 메모리에서 해제가 되면 같이 파괴가 된다. 하지만, 원하는 대로 작동하려면 적절하게 cancel을 호출해줘야 해당 코루틴 작업이 취소된다.
안드로이드는 생명주기와 연관이 깊으므로, CoroutineScope를 권장
Builder ( 코루틴 생성, 코루틴 타입 결정 )
- launch
- runBlocking
Structured Concurrency
- 코루틴 간 계층도
코루틴 스코프 = 코루틴 블럭 = 코루틴 빌더로 생성된 { } 중괄호 영역
코루틴 빌더로 만든 중괄호 내의 영역이 코루틴 스코프(코루틴 블럭)이고, 이 코루틴 스코프의 적용 범위를 지정하는게 GlobalScope같은 개념이다.
Suspend Function
- suspend 키워드
- delay
- join
코루틴 블럭 내에서 각 statement 실행은 순차적이다. 이걸 동시에 하고 싶으면 async await으로 하면 된다.
(추가설명이 필요하다면 : https://hevton.tistory.com/809)
코루틴 취소에 대해서는 본 글에서 다루지 않았다.
(부모 코루틴을 종료하면 자식 코루틴도 알아서 종료된다는 점만 알아두자)
+ child에서 exception이 던져져서 취소되면, exception은 parent로 전파되어서 parent를 취소시킨다. child가 명시적인 취소로 인해 취소되면 parent로 취소가 전파되지 않는다.
+ 부모 코루틴은 자식 코루틴이 모두 종료될 때 까지 알아서 기다린다 (join 사용 하지 않아도)
GlobalScope와 runBlocking은 주의해서 사용해야 한다.
GlobalScope : Exception에 대한 핸들링도 떨어지고, 의도치 않은 실행으로 이어질 수 있다. LifeCycle 이 전역이기 때문에 Structured Concurrency를 이용해야한다. Structured Concurrency를 이용하면 자식 코루틴 내의 Exception을 부모로 전파하여, 리소스를 잘 핸들링하면서 안전한 종료를 유도할 수 있다.
runBlocking : 메인 스레드가 blocking 될 수 있기 때문이다.
suspend fun은 1. 코루틴 스코프(블럭) 내, 2. suspend fun 내에서만 사용 가능.
코루틴은 데몬스레드의 개념처럼, 메인함수가 끝나면 = 프로세스가 끝나면 코루틴도 자동 종료된다.