이전 글 까지는 셀레니움을 이용한 웹 크롤링을 진행했는데
알다시피 셀레니움은 브라우저 기반 동작이기 때문에 속도가 좀 느리다.
속도 방면에서 성능을 끌어올리기 위해서 BeautifulSoup 와 Requests를 이용한 웹 크롤링 방법이 있다.
대신 Selenium을 이용할 때 보다, 조금 더 HTML과 CSS 쪽의 지식이 필요하다.
BeautifulSoup : 웹 페이지의 정보를 쉽게 스크래핑 할 수 있는 라이브러리
Requests : HTTP 요청을 보낼 수 있는 기능을 제공하는 라이브러리
저는 파이참을 이용하여 개발했습니다.
파이참 콘솔 창에 두 줄을 입력해서 라이브러리를 설치해줍니다.
pip install beautifulsoup4
pip install requests
이전 시간에 Selenium을 이용해서 이마트에서 상품명과 상품가격을 크롤링하여 pandas 툴로 정리하여 출력한 적이 있는데
이걸 이번엔 BeautifulSoap와 requests를 이용해 구현해봅니다.
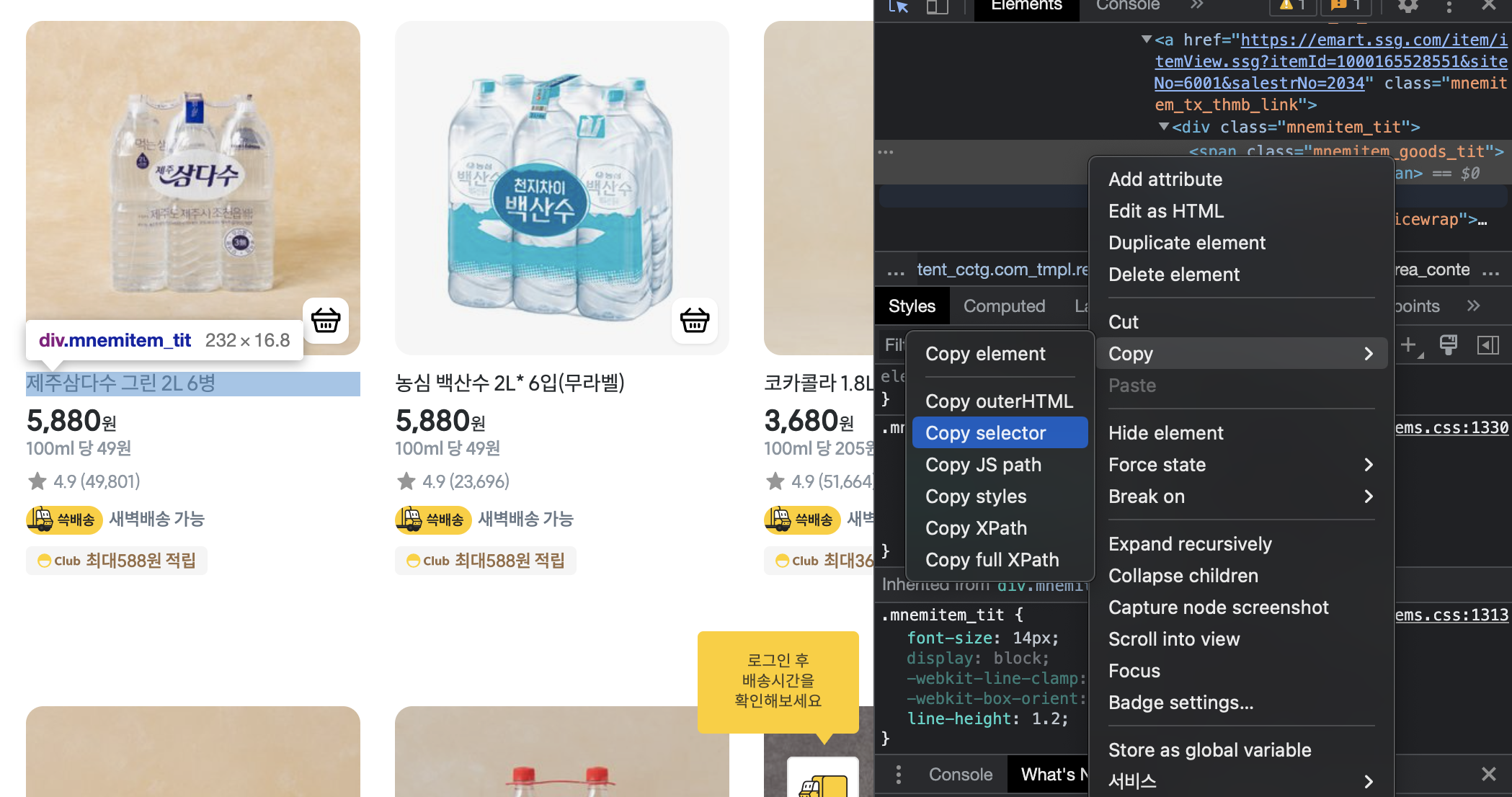
상품명의 Copy selector를 진행해줍니다.
그리고 그 다음 상품까지 또 똑같이 Copy selector해서 비교해봅니다.
그리고 이 둘을 출력해보면 아래와 같습니다
#ty_thmb_view > ul > li:nth-child(2) > div > div > div.mnemitem_detailbx > div.mnemitem_tx_thmb > a > div.mnemitem_tit > span
#ty_thmb_view > ul > li:nth-child(3) > div > div > div.mnemitem_detailbx > div.mnemitem_tx_thmb > a > div.mnemitem_tit > span나머진 다 똑같은데, li:nth-child(2) 와 li:nth-child(3) 에서 숫자 부분만 다른 것을 알 수 있습니다.
li:nth-child(2) 에서 :nth-child(2)는 특정 상품명을 칭하는 것이므로, 우리는 이 태그들의 관계를 통해 공통된 태그를 갖는 정보를 모두 불러올 것이기에 :nth-child(2) 부분을 지웁니다.
#ty_thmb_view > ul > li > div > div > div.mnemitem_detailbx > div.mnemitem_tx_thmb > a > div.mnemitem_tit > span또한, 위 태그 관계들 속에서 가장 마지막이 span으로 나와 있는데
소스코드를 보면 span을 가리키는 것이 두 가지가 있습니다.
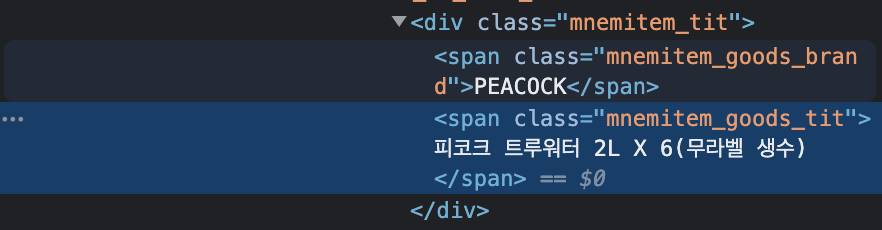
따라서 span 중에서도 특정하기 위해서 class 정보까지 넣어주면
#ty_thmb_view > ul > li > div > div > div.mnemitem_detailbx > div.mnemitem_tx_thmb > a > div.mnemitem_tit > span.mnemitem_goods_tit이렇게 됩니다.
span 을
span.mnemitem_goods_tit 로 수정한 것입니다.
이렇게해서 태그에 클래스까지 매핑해주어서 좀 더 정확하게 특정지을 수 있습니다.
from bs4 import BeautifulSoup as bs
import pandas as pd
import requests
page = requests.get('https://emart.ssg.com/disp/category.ssg?dispCtgId=6000213424')
soup = bs(page.text, "html.parser") # 응답받은 page 내용을 beautifulsoup에서 사용하기 위한 변환
# 태그 내의 관계성을 기반으로
product_name = soup.select('#ty_thmb_view > ul > li > div > div > div.mnemitem_detailbx > div.mnemitem_tx_thmb > a > div.mnemitem_tit > span.mnemitem_goods_tit')
product_price = soup.select('#ty_thmb_view > ul > li > div > div > div.mnemitem_detailbx > div.mnemitem_tx_thmb > a > div.mnemitem_pricewrap > div > div.new_price > em')
product_name = [ (du.text) for du in product_name] # list comprehension
# print(product_name)
product_price= [ (du.text) for du in product_price] # list comprehension
# print(product_price)
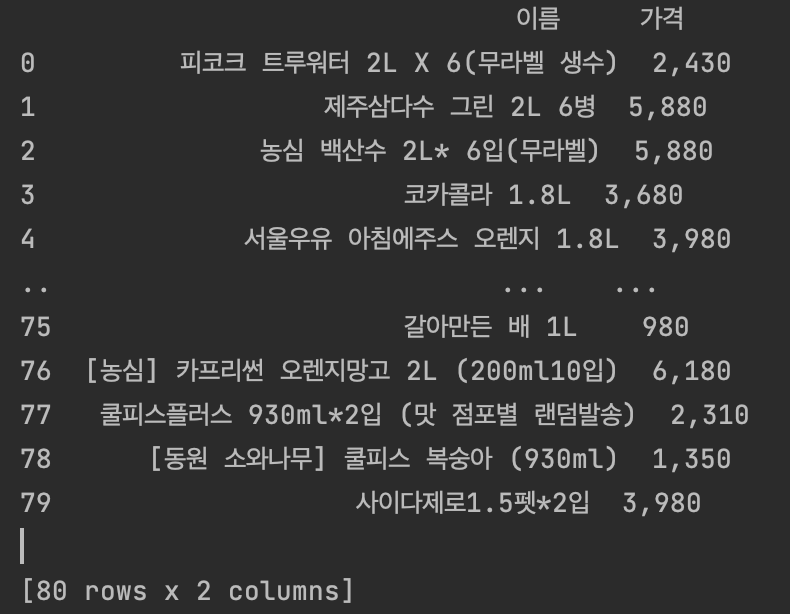
df = pd.DataFrame({'이름': product_name, '가격':product_price});
print(df)
#ty_thmb_view > ul > li:nth-child(2) > div > div > div.mnemitem_detailbx > div.mnemitem_tx_thmb > a > div.mnemitem_tit > span
#ty_thmb_view > ul > li:nth-child(3) > div > div > div.mnemitem_detailbx > div.mnemitem_tx_thmb > a > div.mnemitem_tit > span
# -> nth-child(2) 부분 없애지고, span이 두개가 있기에, span.class명 == span.mnemitem_goods_tit 로 해서 특정해줌.
참고로
lis = soup.find_all(class_='mnemitem_goods_tit');
이렇게 class만을 특정하여서 간단하게 구현해볼 수도 있는데, 이렇게 하면 페이지에 따라 원치 않은 결과까지 가져올 수도 있다.
예로, 이마트 페이지에서 기본 상품들의 리스트만 가져오고 싶은데
이마트에서 홍보 상품들까지 이 클래스로 관리하고 있어서, 홍보 상품들까지 모두 가져오게 되었다.
따라서 맨 위에서 구현했듯 selector를 이용하여 조금 더 구체적으로 지정해 주는 것이 더 정확하긴 하다.
참고
https://beomi.github.io/gb-crawling/posts/2017-01-20-HowToMakeWebCrawler.html
https://rednooby.tistory.com/98
'[Python & Ruby]' 카테고리의 다른 글
| Python 크롤링 - BeautifulSoup로 네이버 검색어 크롤링 (0) | 2022.12.01 |
|---|---|
| Python 크롤링 - 3 / 이마트 크롤링해보기 4 (0) | 2022.11.26 |
| 파이썬 datetime 날짜 차이 / 날짜 덧셈 / 날짜 파싱 (0) | 2022.11.26 |
| Python 파이참 셀레니움 드라이버 설치 / 환경 세팅 (1) | 2022.11.20 |
| Python 크롤링 - 3 / 이마트 크롤링해보기 3 (0) | 2022.11.20 |

