이전 글 : [Kotlin + Spring] 1. 새 프로젝트 시작 (NginX 연동까지)
이번에는 이전 글에 이어서 Spring data JPA 를 활용해보겠습니다.
MySQL을 사용할 것이므로, 아직 설치하지 않으신 분은 이 글을 통해 설치하고 와주세요
먼저 Spring Data JPA와 Mysql Connector 두 개의 dependency가 필요합니다.
implementation("org.springframework.boot:spring-boot-starter-data-jpa")
runtimeOnly("com.mysql:mysql-connector-j")
Spring data JPA
JPA는 ORM 프레임워크입니다.
ORM은 객체와 데이터베이스 테이블을 1:1로 매핑해주는 프레임워크로, 객체지향적인 세계와 테이블 세계를 연결해준다고 보면 됩니다.
JDBC를 통해 프로그램과 데이터베이스를 통신할 수 있고, 두 통신 간에 ORM 프레임워크를 사용하여 더 편한 설계를 진행할 수 있습니다.
ORM을 사용하지 않으면 객체와 테이블을 직접 매핑해주는 등 쿼리문도 모두 수작업으로 작성해줘야 합니다.
물론 복잡한 쿼리의 경우, ORM을 사용하더라도 직접 쿼리문을 작성해줘야 하는 경우도 물론 필요합니다.
JPA를 구현한 구현체가 Hibernate 라는 것이고, Hibernate 중에 Spring에서 쓰이는 것들을 쉽게 모아준 것이 Spring Data Jpa입니다.
다시 돌아와서, 다음과 같은 경로에 application.properties 파일이 있을 텐데요
이걸 application.yaml 로 바꿔준 뒤에 내용을 다음과 같이 수정해줍니다. (참고로 yml과 yaml은 같습니다)
 |
|
// application.yaml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
# DB Source URL
url: jdbc:mysql://127.0.0.1:3306/{DB명}?useSSL=false&useUnicode=true&serverTimezone=Asia/Seoul
# jdbc:mysql://<IP>:<Port/<DB>?useSSL=false&useUnicode=true&serverTimezone=Asia/Seoul
#DB Username
username: {DB유저명}
#DB Password
password: {DB비밀번호}
jpa:
show-sql: true
#DDL
hibernate:
ddl-auto: update
# JPA
properties:
hibernate:
format_sql: true🔥위 항목 중에 {} 로 감싼 것들은 개인에게 맞는 값으로 변경해줘야 합니다🔥
특히나 Spring data jpa에서는, 객체를 설계하면 테이블은 자동 생성 되지만 DB는 생성되지 않으므로
DB를 먼저 생성해 준 뒤에 서버를 실행해줘야 합니다.
위에 보는 바와 같이, 스키마를 {DB명}으로 지정했으므로
CREATE DATABASE {DB명}를 통해 database를 생성해줘야합니다. (mysql은 대소문자 구분 없음)
mysql 먼저 실행해주시고
brew services start mysql
mysql 로그인해주시고
mysql -uroot -p
DB를 생성해줍니다.
CREATE DATABASE 생성하실DB명;
완료되었으면 다시 IntelliJ로 돌아와서
entity 패키지를 만들고, 그 아래에 User 클래스를 생성해줍니다.
@Entity
class User(
@Id
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long? = null,
@Column(name = "email", length = 50, unique = true)
var email: String? = null,
@Column(name = "fcm_token", length = 300)
var fcmToken: String? = null,
@Column(name = "password", length = 100, unique = true) // uid로 사용할 예정
var password: String? = null,
@Column(name = "nickname", length = 50)
var nickname: String? = null,
@Column(name = "activated")
var isActivated: Boolean = false,
@ElementCollection
var blackList: MutableSet<String> = mutableSetOf(),
)
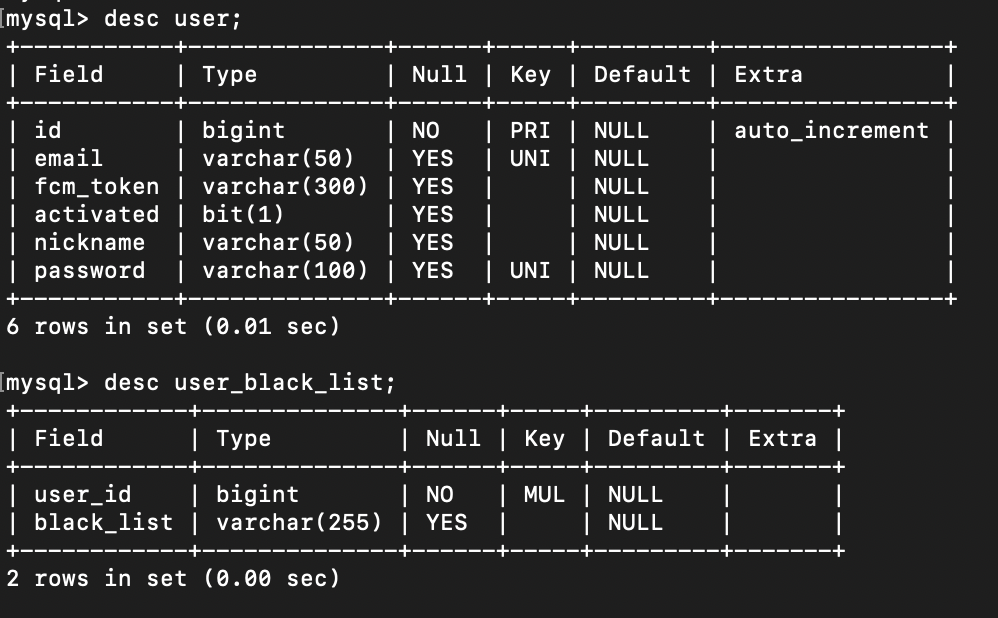
@Entity가 붙은 클래스는 JPA가 관리하는 클래스입니다. 테이블과 매핑할 테이블에 이 어노테이션을 붙입니다.
즉, 이 Class 파일이 곧 테이블 정보가 됩니다.
@Column을 지정하지 않으면 기본적으로 변수명이 필드명이 되지만, mysql은 대소문자를 구분하지 않고, 필드명으로 snake case를 사용하고 있으므로, Column을 통해 DB에서 사용될 필드명을 따로 지정해줍니다.
또한 리스트 형식의 데이터를 저장하기 위해서는 @ElementCollection 어노테이션을 붙여줍니다.
이렇게 저는 제 프로젝트에 필요한 정보들을 모두 지정해줬습니다.
추후 JWT 토큰을 도입하면서 Authority에 대해서도 진행할 예정입니다.
이러고 다시 어플리케이션을 실행하면 두 개의 테이블이 생성된 것을 확인할 수 있습니다!
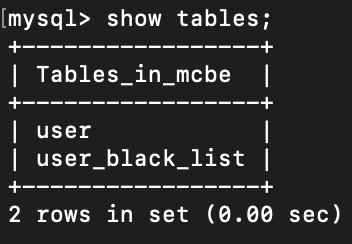
여기서 우리는 한 가지 정보를 알 수 있습니다. List 형식의 필드를 사용하기 위해 @ElementCollection으로 지정할 경우
해당하는 새로운 테이블로 관리된다는 사실!
즐겁네요
Cherry pick
그리고 이걸 커밋하는 과정에서 하나 실수를 해서 체리픽을 사용해보도록 하겠습니다.
위 변경사항을 main -> develop -> feature_jpa 에 적용해야 했는데
main에 작성하고 커밋해버렸습니다.
그럼 우리는 이전 커밋으로 돌아갑니다.

돌아간 뒤에 git checkout -b develop으로 develop 브랜치를 만들어줍니다.

그럼 develop의 head는 여기에 가 있죠?
여기서 한번 더 git checkout -b feature_jpa 브랜치를 만들어줍니다.

그럼 이렇게 되죠?
여기서 feat(User): 유저 테이블 생성 커밋을 feature_jpa로 가져올 거니까 cherry-pick 해줍니다.
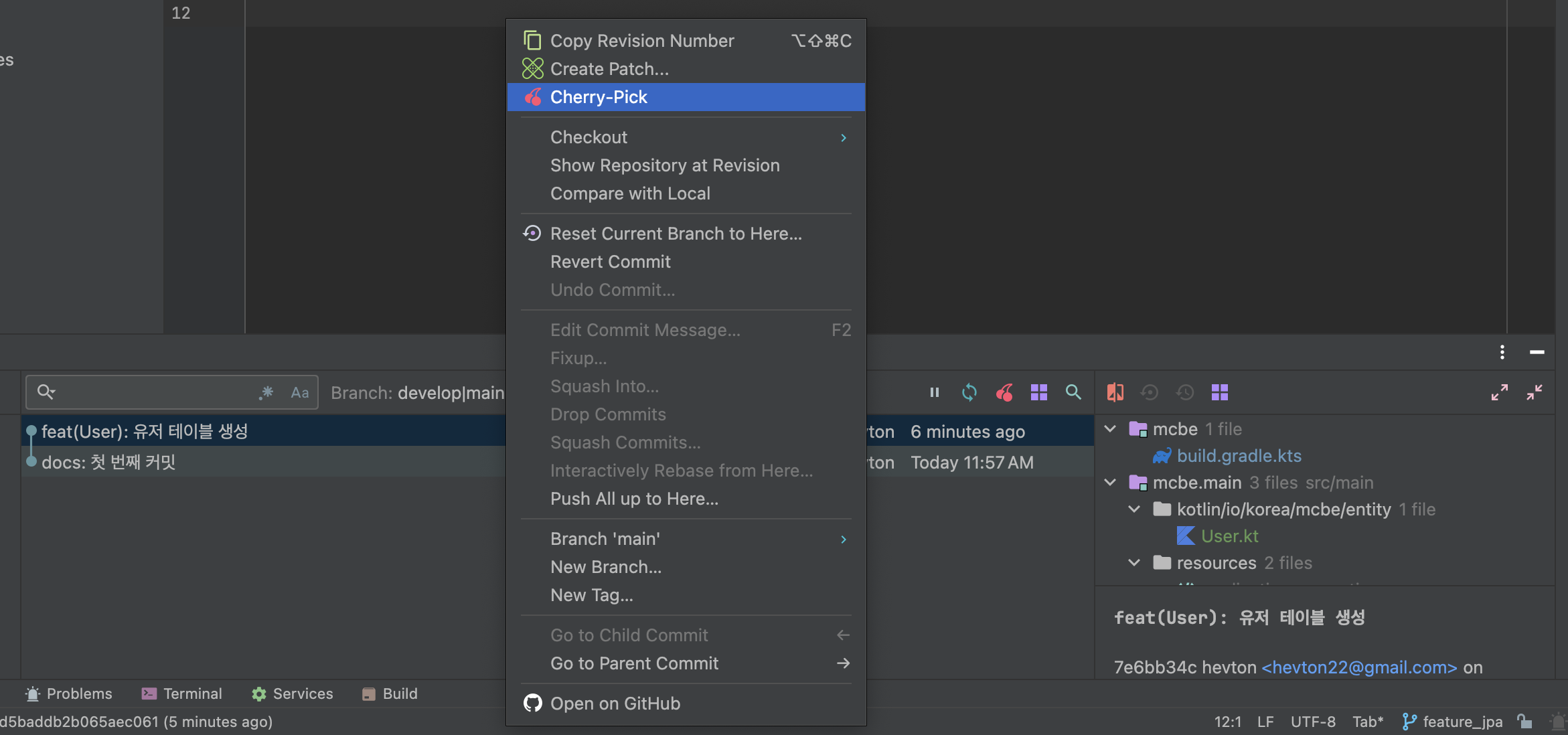
이렇게 되면 main에서 커밋을 복사해서 feature_jpa에 가져온 상황이므로, main에 있는 커밋을 지워줍니다.
rest hard로 커밋을 날려줍니다.
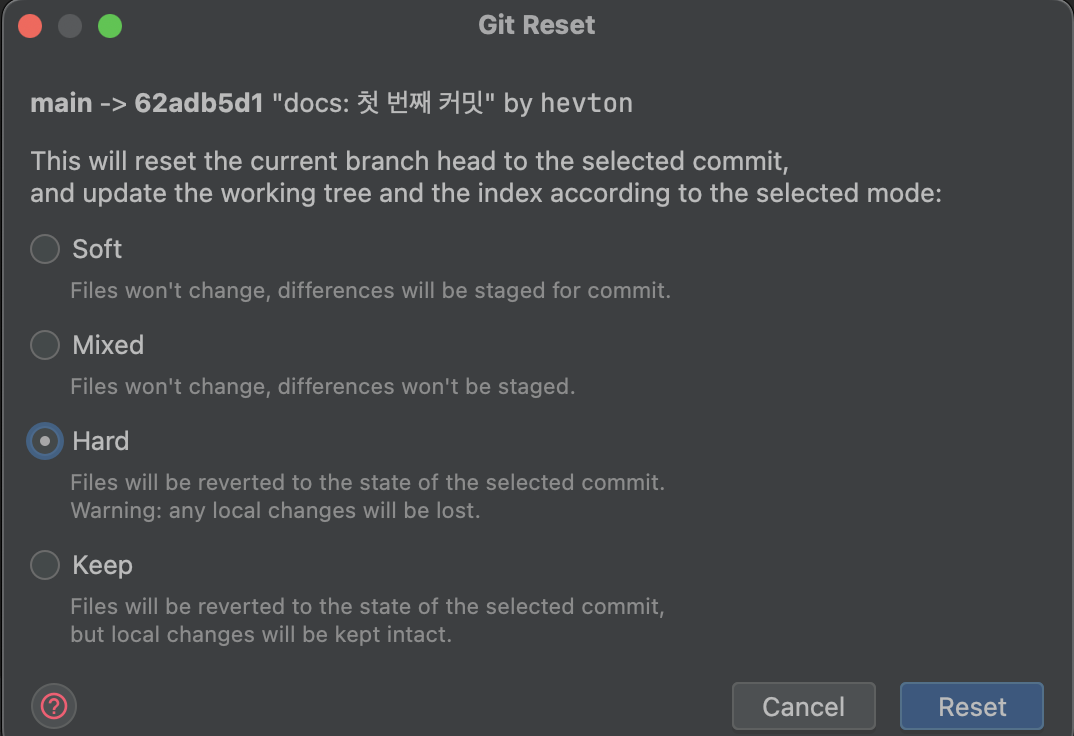
이제 우리가 처음 원하던 상태로 되었습니다.
'[서버] > [SpringBoot Kotlin]' 카테고리의 다른 글
| [Kotlin + Spring] Spring 3.X 버전 QueryDSL 세팅하기 (0) | 2024.04.08 |
|---|---|
| [Kotlin + Spring] 내가 QueryDSL을 도입하게 된 이유 (0) | 2024.04.08 |
| [Kotlin + Spring] 1. 새 프로젝트 시작 (NginX 연동까지) (0) | 2024.03.27 |
| SpringBoot Mysql 프로젝트 EC2에서 Docker로 실행하기 (1) | 2023.04.21 |
| SpringBoot Mysql프로젝트 Docker로 실행하기 (0) | 2023.04.19 |



